跳表是一个比较冷门的数据结构,很多数据结构的书里都不会讲它。但跳表确实是一个很优秀的数据结构,并且经常在面试中被问到,所以我们很有必要了解一下这个数据结构。
本文的主要内容搬运自极客时间专栏。极客时间版权所有: https://time.geekbang.org/column/article/42896
更多关于跳表的内容可以查阅《Redis设计与实现》。
什么是跳表
我们都知道二分查找算法,它依赖的是数组随机访问的特性,所以只能用数组来实现。如果数据存储在链表中,就真的没法用二分查找算法了吗?实际上,我们只需要对链表稍加改造,就可以支持类似“二分”查找算法。我们把改造之后的数据结构叫作跳表(Skip list)。
跳表是一个各方面性能都比较优秀的动态数据结构,支持快速的插入、删除、查找操作,在一些地方甚至可以替代红黑树。比如 Redis 中的有序集合(Sorted Set)就是用跳表来实现的。
对于一个单链表,即便其中存储的数据是有序的,如果我们想在其中查找某个数据,也只能从头到尾遍历链表。这样的查找时间复杂度是O(n),效率比较低。
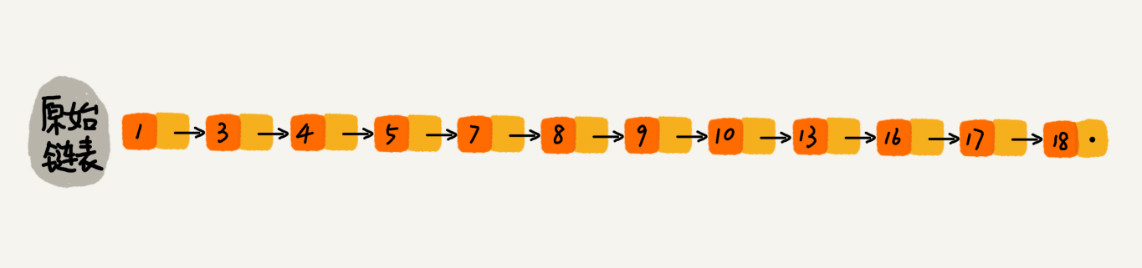
那怎么来提高查找效率呢?可以如下图所示,对链表建立一级“索引”,查找的时候先遍历索引,然后通过索引层的指针找到原始链表,继续查找。
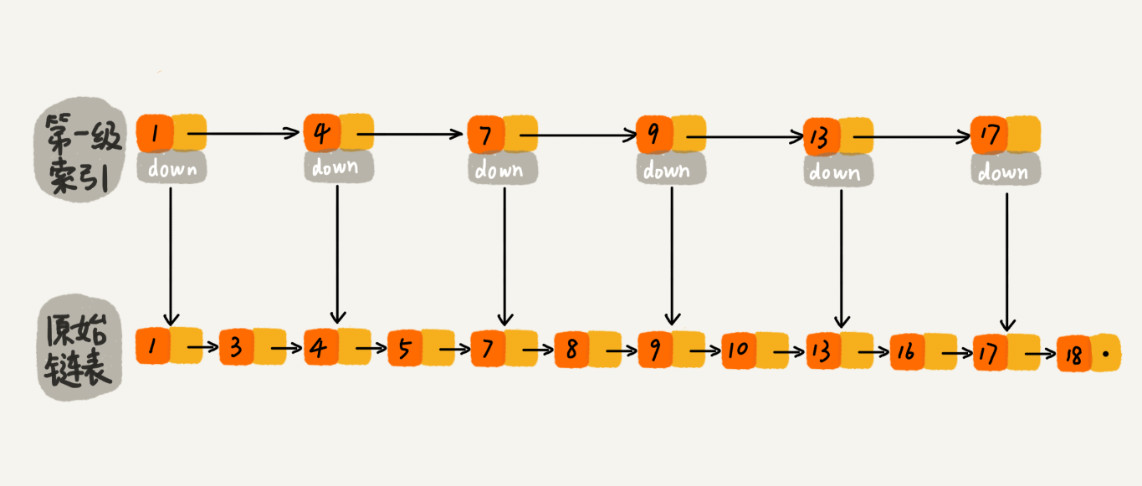
比如要查找16,我们可以现在索引层遍历,当遍历到节点13时,我们发现下一个节点值为17,那么16一定位于这两个节点之间。然后我们通过索引层节点13的 down 指针,下降到原始链表这一层,继续遍历。这种方式查找到16只需要遍历7个节点(1,4,7,9,13,13,16),而直接遍历原始链接则需要遍历16个节点。查找效率得到了提升。
在此基础上,再加一层索引,在第一级索引中抽取节点组成二级索引。如下图所示:
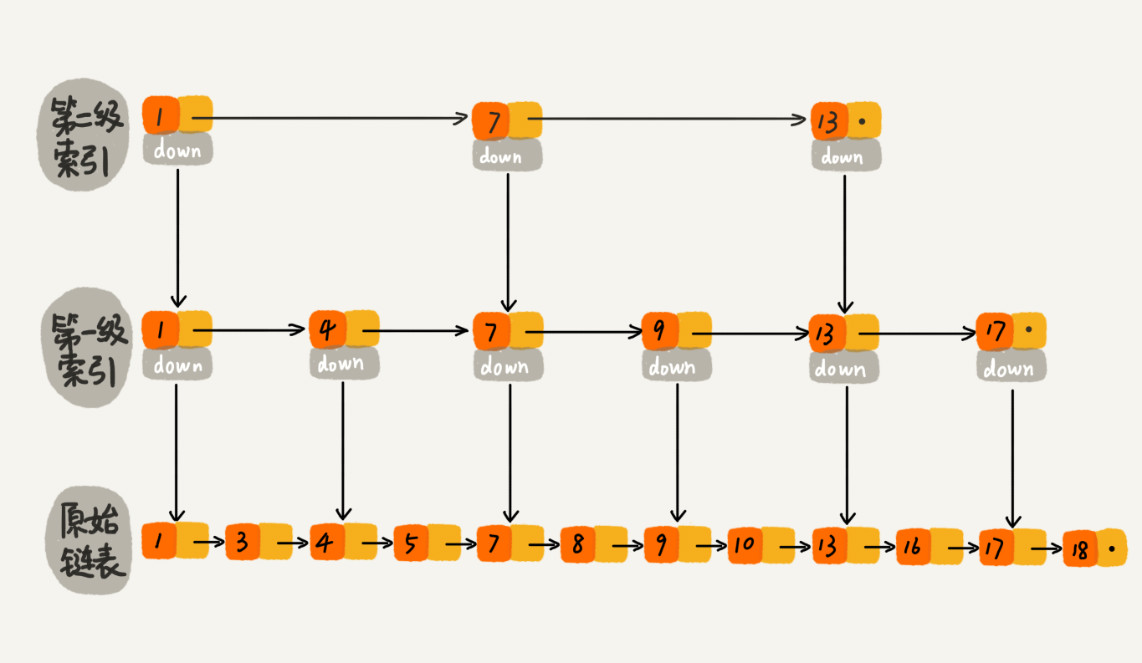
再来查找16,只需要遍历6个节点(1,7,13,13,13,16),再次提升了速度。当数据量很大的时候,这里的效率提升会更加明显。
总结一下:这种链表加多级索引的结构,就是跳表。
跳表的速度
先说结论:跳表查找的时间复杂度为 O(logn)。对比单链表查找的时间复杂度为 O(n),跳表确实提高了查找的效率。
对于一个有 n 个节点的链表,假设每 m 个节点生成一个索引节点,最高层索引有两个节点,那么索引的层数 h = logmn,查找到一个点的时间复杂度就为 O(m*logmn)。通常取 m = 2,时间复杂度为 O(logn)。
根据等比数列的求和,跳表的空间复杂度为 O(n)。在实际的软件开发中,原始链接中存储的节点有可能是很大的数据结构,而索引节点中只用存储关键值和指针,索引占用的额外空间远小于原链表。
跳表索引的动态更新
当不停地往跳表中插入数据时,如果不及时更新索引,就有可能出现两个索引节点之间数据非常多的情况。极端情况下,跳表会退化成单链表。
红黑树、AVL树这样的平衡树时通过左右旋的方式保持子树的平衡。而跳表是通过随机函数来维护“平衡”。当我们往跳表内插入数据时,我们可以同时将这些数据插入到部分索引层。至于插入到哪几级索引层,是通过一个随机函数来确定的。比如随机函数生成了数值 K,那么就将这个节点添加到第一级到第 K 级索引中。
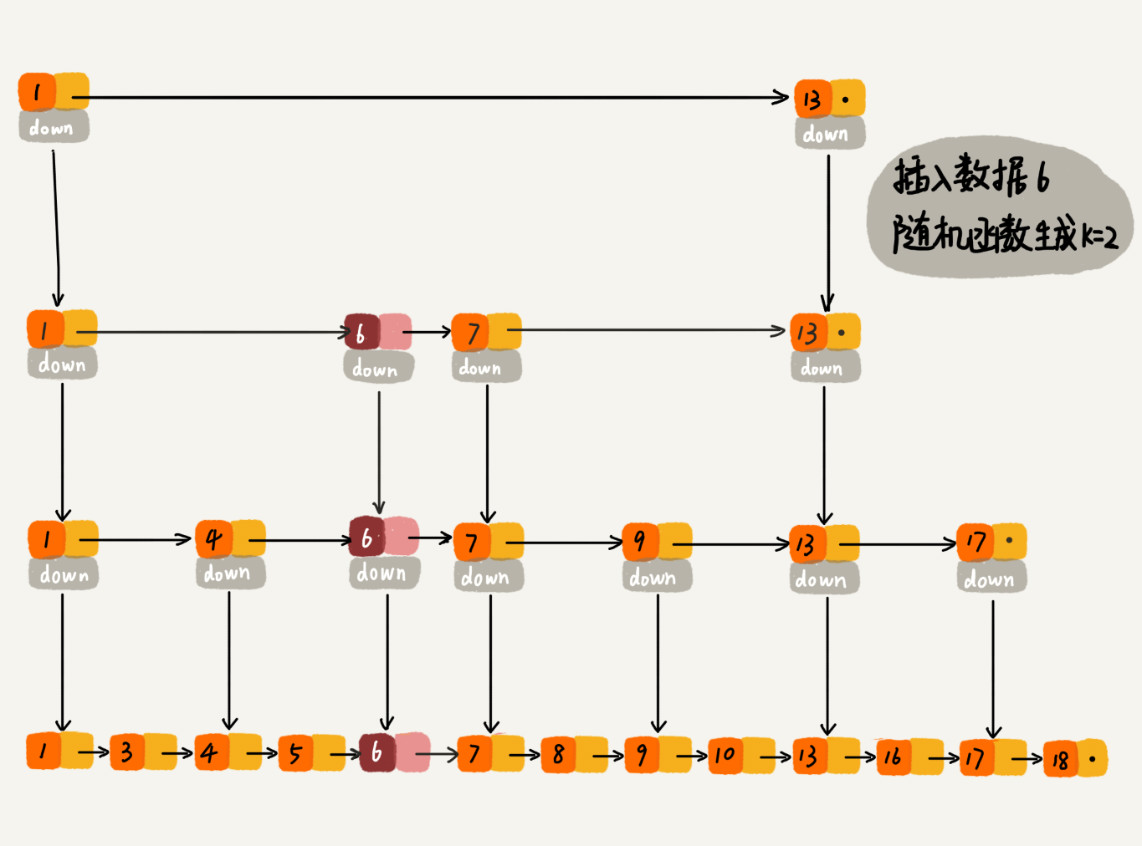
随机函数的选择可以参考Github 上这段代码或者 Redis 中关于有序集合的跳表实现(zslRandomLevel(void))。
以上。